Tracing the history of the earliest neural network

The year was 1958 when the United States Navy unveiled what they called a thinking machine – a perceptron. It was an IBM 704 equipped to “react” to and learn from its inputs. The giant computer simulator was the brainchild of Frank Rosenblatt, a scientist at Cornell University. In an interview with The New Yorker, Rosenblatt said, “Simply put, the perceptron is a self-organised machine that can learn.” He felt that the perceptron would become the technology closest to resembling the human brain. It laid, in some sense, the foundation for the era of artificial intelligence (AI).
But why did it take nearly half a century after Rosenblatt’s perceptron to unleash the true power of AI? A key reason is an age-old tale of scientific rivalry. American scientists Seymour Papert and Marvin Minsky, who were sceptics in the field, questioned Rosenblatt’s claims about the perceptron’s learning abilities, and even came up with alternative proofs for the limitations of the perceptron’s functionality. All of this diluted the hype around the perceptron’s development.
Today, AI has changed the way we perceive the world. AI tools can now flawlessly transcribe text in native languages, break down a dense scientific paper in seconds, create artificial art, and compose a poem. To understand the origins of this marvellous modern technology, let us rewind to six decades ago.
The first “learning” machine
In the 1940s, English mathematician and computer scientist Alan Turing was working on building a machine that could “think” – a feat that remained unachievable in his time. From that time, scientists have been drawing inspiration from the human brain to design a machine that could exhibit signs of learning.
A key insight from the human brain was the functioning of neurons. “Biological neurons have an all-or-none property; they either fire or do not fire,” explains Sitabhra Sinha, Professor at the Institute of Mathematical Sciences, Chennai. This meant that every neuron has just two states, an ON and an OFF state. Thus, the simplistic model of a neuron could be depicted as an electrical switch. American scientists Warren McCulloch and Walter Pitts used this logic and constructed the very first ‘switch neuron’, a simulated computer model in 1943, using the binary code of ON (firing neuron) and OFF (non-firing neuron) states.
McCulloch and Pitts demonstrated the simplest logic behind the functioning of the biological neuron. However, just switching on the neuron was not enough to achieve learning. In 1958, Frank Rosenblatt finally achieved this triumph by building a computer called the Mark I Perceptron, with a built-in programme functioning as a pattern classifier – it could learn to distinguish between different patterns.
The perceptron became the first supervised learning machine
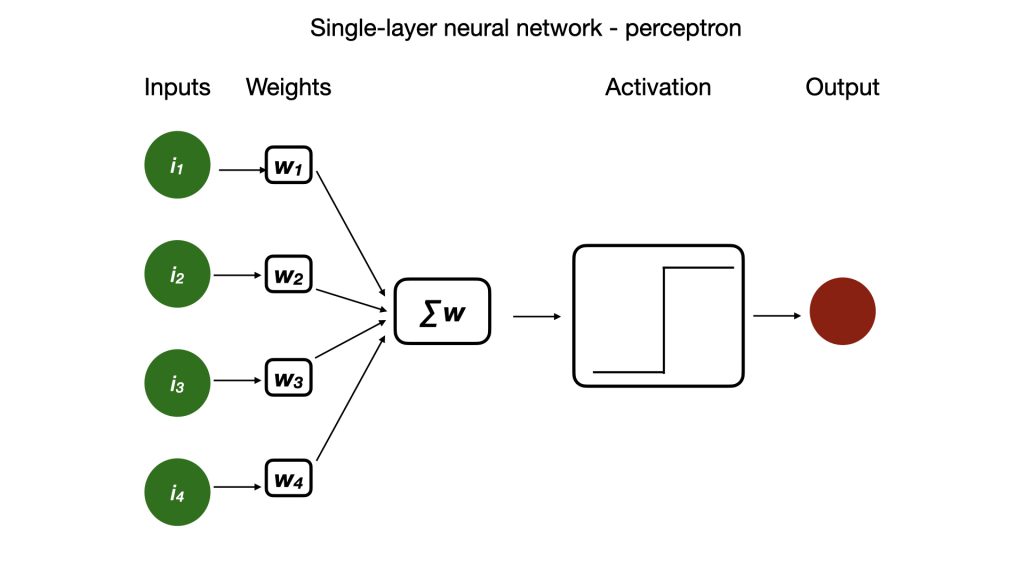
The perceptron became the first supervised learning machine. Rosenblatt created a series of neurons that switched ON and OFF. He connected them using a binary logic gate (AND and OR gate). Then, to achieve learning, each of the switch neurons was given a random value (an activation energy, also called weight) which determined when it would switch ON, similar to how biological neurons require a certain activation energy to fire. “The activation energies have a threshold value beyond which they activate, directing the firing properties of the network,” adds PS Sastry, Honorary Professor at the Department of Electrical Engineering, IISc.
This allowed the series of switch neurons to store the learned pattern. And the series came to be called the single-layered neural network. “The perceptron is the basis of most artificial neural networks that we see today,” emphasises Rishikesh Narayanan, Professor at the Molecular Biophysics Unit, IISc.
Rosenblatt’s innovation wasn’t in the development of the neural network structure, but in the implementation of the learning rule. When the neural network encounters a pattern (input), it attempts to learn it. This results in the alterations of the activation energies associated with each subunit of the network. “By iteratively tuning these weights (activation energies), the perceptron was able to classify data, which is represented as the output,” says Sastry. Whenever the network was shown a particular pattern, it recognised it, and as an output produced a YES or NO answer.
“The perceptron could only solve linear equations,” explains Sitabhra. “[But] it failed to solve the infamous XOR [Exclusive OR] problem, whose solutions are non-linear,” adds Sastry. The single-layer perceptron could learn the difference between simple logic gates (simple linear function). But its limitations arose when the logical reasoning was not bound by AND and OR gates.
The XOR problem was a classic example of this. In XOR, the answer is YES only when two inputs are different [such as (0, 1); (1, 0)]. However, it is a NO when the inputs are similar [such as (0, 0); (1, 1)]. If we plot the four possible input combinations on a 2D graph, the YES outputs (0, 1 and 1, 0) and the NO outputs (0, 0 and 1, 1) are diagonally opposed, and the solution for this can never be a straight line. The Mark I Perceptron, the single-layered neural network, could never solve this.
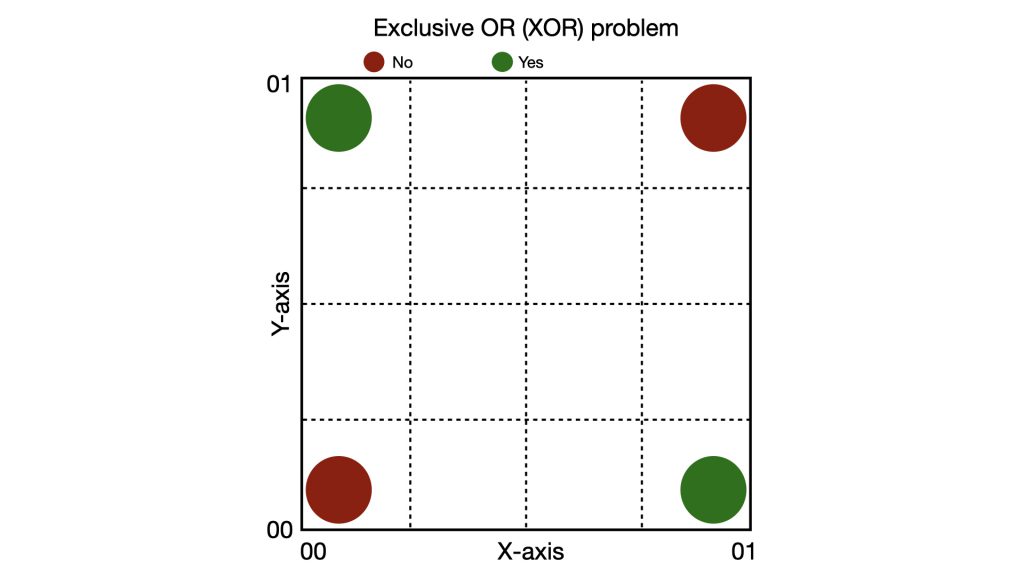
Graphic depicting the XOR problem (Image: Aishwarya Segu)
Marvin Minsky, co-founder of the AI lab at the Massachusetts Institute of Technology (MIT), and Seymour Papert, a mathematician from MIT, critiqued this flaw of the single-layered perceptron with a sharp mathematical argument in their book titled Perceptrons: An Introduction to Computational Geometry, published in 1969. This critique of perceptrons triggered the first AI winter – a long hiatus in neural network research – which simultaneously resulted in a reduction in monetary funding for neural network research. Unfortunately, the untimely death of Rosenblatt in 1971 further stalled developments in the field.
This critique of perceptrons triggered the first AI winter – a long hiatus in neural network research – which simultaneously resulted in a reduction in monetary funding for neural network research. Unfortunately, the untimely death of Rosenblatt in 1971 further stalled developments in the field.
“Like the phoenix, I rise”
Fifteen years after Rosenblatt’s death, the AI winter turned when scientists finally modified neural networks to solve the XOR problem. For this, they added a second, hidden layer of inputs to Rosenblatt’s single-layer neural network.
This hidden layer was the key to breaking the linearity barrier. “It laid the foundation for modern deep-learning tools,” says Sastry. The problem with the single-layer neural network was the absence of a method to identify failures and errors when the solution was not linear. One way to solve this problem was by developing a method to convey the error back to the initial input layer for correction. To evaluate this error, scientists built a step-by-step computer programme or algorithm.
“This was called the backpropagation algorithm,” explains Sitabhra. It first identifies the error in the output stage and backtracks the error to the input layer through the hidden layer. This process results in precise adjustments to the initial weights, which ultimately can produce the desirable solution for nonlinear functions.
Seppo Linnainmaa, a Finnish mathematician, first postulated the mathematical proof for backpropagation using calculus in 1970. But it was Paul Werbos, a PhD student at Harvard University in 1974, and Shun’ichi Amari, a Japanese neuroscientist in the 1980s, who independently described the application of backpropagation as a training method for multi-layered perceptrons.It is possibly the most influential work on modern-day multi-layered neural networks.
Finally, in a 1986 paper titled ‘Learning representations by back-propagating errors,’ American scientists David Rumelhart and Ronald Williams, and British-Canadian scientist Geoffrey Hinton provided the compelling experimental and mathematical proof of multi-layered perceptrons. It is possibly the most influential work on modern-day multi-layered neural networks.
Simultaneously, in 1982, American physicist John J Hopfield developed an alternative approach to solving complex problems using neural networks. Multi-layered networks are feedforward networks – information moves in only one direction, from input to output. In contrast, Hopfield built a recurrent neural network, which was still single-layered. In a recurrent network, all neurons are connected to all other neurons at all times, with symmetric activation energies, instead of random as seen in Rosenblatt’s design. The neurons still behaved as switches.
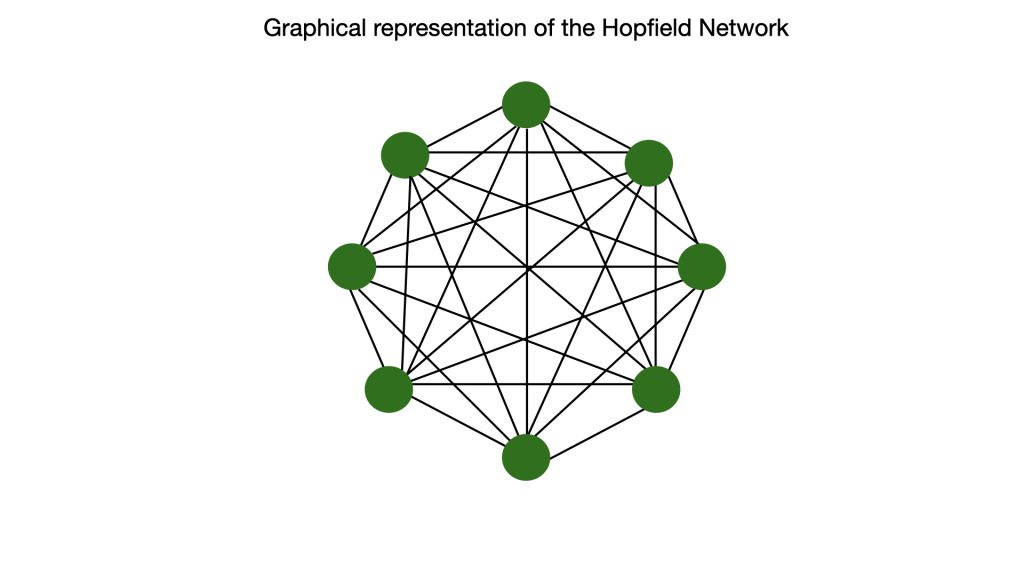
As the neurons were all connected, a change in the activation energies during learning results in overall changes in the network. This also means that the energy of the network changes. Thus, the network can have multiple energy states, resulting in hills and valleys corresponding to high and low energy states. When a pattern is recognised by the network, it attains the lowest energy function (a valley). Because this is a stable state of energy, it can learn and memorise it.
The Hopfield network became a key to visualising associative memories and patterns. Hopfield and Hinton received the 2024 Nobel Prize in Physics for their contribution to neural networks. By adding a third layer, perceptrons could now solve non-linear functions, and by developing recurrent neural networks, scientists were able to write algorithms capable of modern pattern recognition.
The power of computation
The idea of building thinking machines did not begin with the invention of the computer but with a fundamental question: Can human thought be reduced to a logical process? But with the advent of the multi-layered neural networks, the field required greater computational power to achieve the possible computations.
“In our times [in the 1990s], we largely had 3-4 layers, and to add even a single neuron in the layer – forget about a layer – we thought 100 times, only because of the number of computations it increased, for which machines were not available,” recalls Rishikesh.
The next essential step in neural network research was to achieve the computational power required to run the algorithms. This became possible because of Parallel Distributed Processing (PDP), developed during the mid-1980s. Until then, computers ran neural networks sequentially; PDP changed that notion. It allowed operations to be performed concurrently, distributing computations across multiple processors. This exponentially enhanced the computational abilities of the machine learning models.
In the late 1990s, scientists realised that Graphics Processing Units (GPUs) – originally designed to perform thousands of parallel matrix multiplications for rendering video game graphics – were best suited for the parallel computations required by backpropagation. The use of GPUs to train artificial neural networks began in the early 2000s, officially lifting the AI winter. Simultaneously, the rapid growth of the semiconductor industry enabled cheaper hardware components needed for the processors.
Artificial neural networks could now recognise patterns including alphabets, pictures, and even voices. The true inflection point came in the early 2020s, when widespread development and access to AI models and applications unleashed its full power, making AI a household term overnight.
The journey of the perceptron is a testament to the complex, non-linear nature of scientific progress
The journey of the perceptron is a testament to the complex, non-linear nature of scientific progress. It wasn’t without conflict. “Minsky and Papert were excellent critics of the field,” says Rishikesh. But some scientists think that they may have tried to kill perceptron research during the late 1970s and perhaps delayed the timeline of AI’s evolution.
Sitabhra adds that such a debate is ultimately a “chicken and egg problem” where the contributions of both theories have equal merit. “Without Minsky’s critique, we would not have maybe developed transformers, an essential part of neural engines,” he adds. Today’s AI tools use both Rosenblatt’s and Minsky and Papert’s approaches. “The vast, powerful networks learn patterns from data, while symbolic methods provide structure,” explains Sastry.
Rishikesh cautions that while AI can do a lot, its use as a “mimicry of biological intelligence is falsification.” As Papert once pointed out in his essay published in the journal Daedalus: “Artificial intelligence should become the methodology for thinking about ways of knowing.”
Aishwarya Segu is a PhD graduate from IISER Thiruvananthapuram and a former science writing intern at the Office of Communications, IISc
(Edited by Ranjini Raghunath)